
📸 Build a local and offline-capable chatbot with WebLLM | web.dev
What is WebLLM? — Running AI in the Browser Without a Server
Until now, using AI chatbots or coding assistants required cloud servers. But that’s changing. WebLLM is an open-source library that enables running large language models (LLMs) directly inside web browsers—no server needed.
Developed by the MLC AI team, WebLLM leverages the WebGPU API to deliver hardware-accelerated AI inference in the browser. Your data never leaves your device, ensuring complete privacy, while enabling offline functionality—without any API costs.

📸 WebLLM: Bring AI Language Models to Your Browser - Business ...
Why Browser-Based AI? — Advantages of On-Device AI
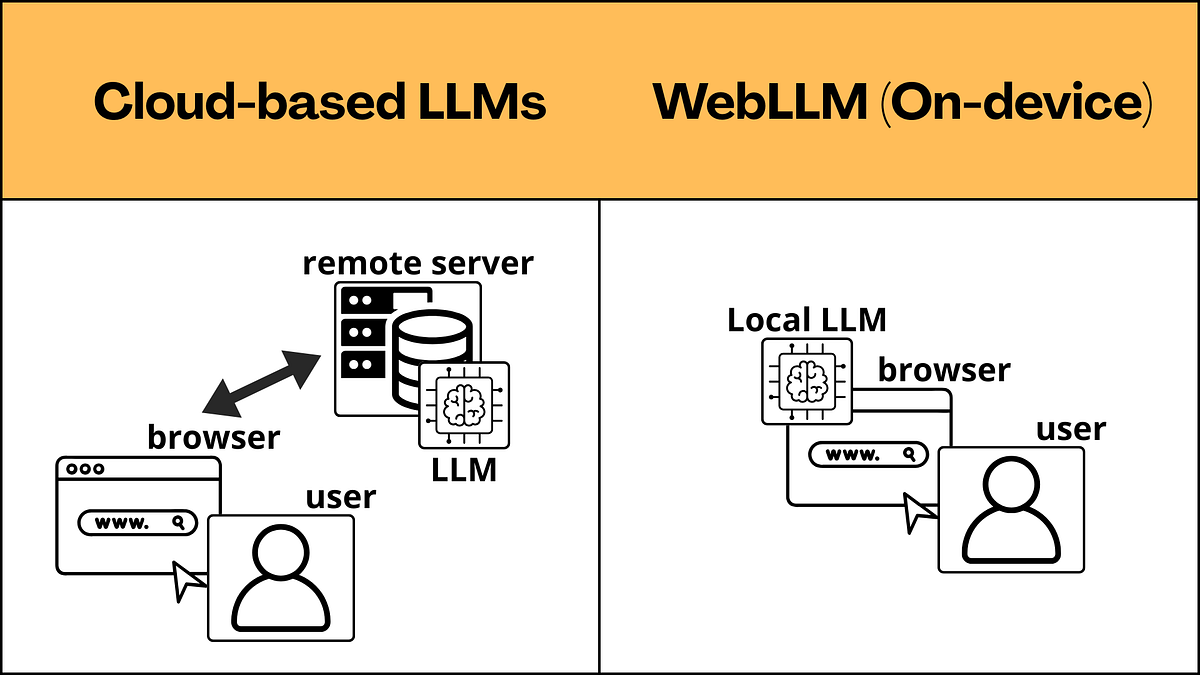
📸 From Cloud to Device: How WebLLM Makes AI Personal and ...
🔒 Complete Privacy
All text, code, and documents you enter never leave your device. Sensitive corporate source code, private medical records, or financial data can be processed with AI—without ever being sent to external servers. This is especially valuable in regulated environments like GDPR or HIPAA.
📸 WebLLM | Home
⚡ Minimal Latency
Processing happens locally—no network round-trips. This ensures fast responses, even with slow or no internet connection.
💸 Zero API Costs
Use AI features unlimitedly—no fees for calling GPT-4, Claude, or other API-based models. Ideal for cost-sensitive startups and independent developers.
🌐 Works Offline
Once downloaded, models work fully offline. Usable on airplanes, underground sites, or remote areas with poor connectivity.
How WebLLM Works: Technical Architecture
WebGPU: The Core Acceleration Technology
The performance secret behind WebLLM is WebGPU. A standardized Web API introduced in 2023, it allows JavaScript to leverage GPU compute power for parallel processing. Compared to WebGL, WebGPU enables 10x faster AI computations.
- Supported on Chrome 113+, Edge 113+, Firefox (Nightly), Safari 18+
- Direct GPU memory management enables running large models
- Optimized parallel matrix operations via Compute Shaders
MLC (Machine Learning Compilation)
WebLLM uses MLC technology, built on Apache TVM, to compile models into WebGPU-optimized formats. This process includes model quantization, reducing memory usage by 4x to 8x.
Supported Models (As of February 2026)
| Model | Parameters | VRAM Required | Key Features |
|---|---|---|---|
| Llama 3.2 3B | 3B | 2GB | Lightweight, fast, general purpose |
| Phi-3.5-mini | 3.8B | 2.5GB | Coding-optimized, developed by Microsoft |
| Gemma 2 9B | 9B | 6GB | Developed by Google, high performance |
| Mistral 7B | 7B | 5GB | Balanced performance |
| Qwen2.5 7B | 7B | 5GB | Strong in Korean and Chinese |
Hands-On Guide: Using WebLLM
1. Installation
npm install @mlc-ai/web-llm
2. Basic Chat Implementation
import * as webllm from "@mlc-ai/web-llm";
// Initialize engine (downloads model on first use)
const engine = await webllm.CreateMLCEngine(
"Llama-3.2-3B-Instruct-q4f16_1-MLC",
{
initProgressCallback: (progress) => {
console.log(`Loading: ${Math.round(progress.progress * 100)}%`);
}
}
);
// Use OpenAI-compatible API for chat
const response = await engine.chat.completions.create({
messages: [
{ role: "system", content: "You are a helpful AI assistant." },
{ role: "user", content: "Hello! Please introduce yourself." }
],
temperature: 0.7,
max_tokens: 512,
stream: true // Supports streaming
});
// Output streaming response
let result = "";
for await (const chunk of response) {
result += chunk.choices[0]?.delta?.content || "";
console.log(result); // Real-time output
}
3. Integration with React
import { useState, useEffect } from 'react';
import * as webllm from "@mlc-ai/web-llm";
function PrivateAIChat() {
const [engine, setEngine] = useState(null);
const [loading, setLoading] = useState(true);
const [progress, setProgress] = useState(0);
const [message, setMessage] = useState('');
const [response, setResponse] = useState('');
useEffect(() => {
async function initEngine() {
const eng = await webllm.CreateMLCEngine(
"Phi-3.5-mini-instruct-q4f16_1-MLC",
{
initProgressCallback: (p) => setProgress(p.progress * 100)
}
);
setEngine(eng);
setLoading(false);
}
initEngine();
}, []);
const handleChat = async () => {
const res = await engine.chat.completions.create({
messages: [{ role: "user", content: message }],
stream: true
});
let text = "";
for await (const chunk of res) {
text += chunk.choices[0]?.delta?.content || "";
setResponse(text);
}
};
if (loading) return <div>Loading AI model... {Math.round(progress)}%</div>;
return (
<div>
<input value={message} onChange={e => setMessage(e.target.value)} />
<button onClick={handleChat}>Send</button>
<p>{response}</p>
</div>
);
}
Real-World Use Cases
🏥 Healthcare & Legal
Analyze patient records or legal documents with AI—without ever sending sensitive data to external servers. Enables full compliance with HIPAA, GDPR, and data protection laws.
💻 Offline Coding Assistant
Enjoy code autocompletion, bug explanations, and documentation generation—even on flights or remote worksites with unstable internet.
🌍 Educational Platforms
Provide AI tutoring in low-connectivity regions, enhancing accessibility and equity in education.
🎮 In-Game AI NPCs
Create responsive, real-time AI characters without server calls—boosting immersion and cutting backend costs.
Limitations & Considerations
- Initial Load Time: First-time model download can be several gigabytes. Subsequent loads use cached data for near-instant startup.
- Hardware Requirements: Requires relatively modern GPUs that support WebGPU. Performance may degrade on older systems or integrated graphics.
- Model Size Limit: Browser memory constraints make models over 10B parameters impractical today.
- Browser Compatibility: WebGPU support is not yet universal across all browsers and operating systems.
Conclusion: The Future of Privacy-First AI
WebLLM is a pivotal technology for democratizing AI. It brings powerful language models to every user—without cloud dependencies, privacy trade-offs, or recurring costs. As of 2026, supported models are mostly small-to-medium scale (3B–9B), but with advancing WebGPU support and hardware improvements, even larger and more capable models will soon run directly in browsers.
If you're building privacy-sensitive applications, offline-first tools, or want to eliminate API costs, WebLLM is ready to explore today.
댓글
댓글 쓰기